Recently I ran across a data centric application that had been written for SQL Server 2005. This particular application had a need to store a lot of large text based data. On the data tier this had been implemented using the text and ntext data types. Given this was a new application that had never looked at an earlier version of SQL Server I was surprised to find that the developers hadn't taken advantage of the new approach to large data types, namely the MAX length specifier for the varchar and nvarchar data types, e.g. using VARCHAR(MAX) to work with up to 2GB of data.
There are a number of advantages to working with the new types over the old. There is support for most, if not all, string functions and they can also be used when declaring variables.
I wonder if these new large data types are yet to become widely known by developers, or if it is simply a case of us all being comfortable with known ways of meeting a particular requirement and following familiar patterns.
Wednesday, December 16, 2009
Monday, December 14, 2009
Denormalisation and transactions
I'm all for denormalising a data model for performance or meeting business requirements with less complexity in the model. I'm happy to design a model with an aggregated figure from a related child table in a parent table - putting a year to date sales figure into a master customer table is one that seems to crop up regularly. One of my rules of thumb when I denormalise is to make sure that I transactionalise units of work to ensure that data integrity is maintained. In the case of the earlier example this would mean placing the insert, update or delete to the sales table inside the same transaction as the update to the year to date sales figure in the customer table. It's critical that the two parts to the data change either succeed completely or fail completely. If the first sales data is changed but the customer year to date sales figure is not (due to some failure) then without a rollback of the transaction your data now has problems. I've seen enough cases where a denormalised data model is used without transactions around units of work to wonder if some developers simply don't realise that this problem even exists.
By the way, you could also use triggers to protect your data integrity. It's not my preferred way of doing things - but it does make for a workable solution.
One other thing that I've found useful (if you inherited a denormalised model that doesn't make use of transactions) is to have a means of recalculating any aggregate values (that might be stored in the data model) by summing across the granular child rows. Having components that do this gives you the flexiblity to check the stored aggregate values from time to time or, in the event that the data does develop problems, you can calculate what the stored aggregate values should be and make the necessary updates.
By the way, you could also use triggers to protect your data integrity. It's not my preferred way of doing things - but it does make for a workable solution.
One other thing that I've found useful (if you inherited a denormalised model that doesn't make use of transactions) is to have a means of recalculating any aggregate values (that might be stored in the data model) by summing across the granular child rows. Having components that do this gives you the flexiblity to check the stored aggregate values from time to time or, in the event that the data does develop problems, you can calculate what the stored aggregate values should be and make the necessary updates.
Friday, December 11, 2009
Lazy Installation Scripts
One of my pet hates is working with installation / update scripts which don't check if objects exist before trying to drop them.
This is just lazy and (when) lots of objects are involved it makes reviewing the installation logs difficult due to the large number of "Cannot drop the view...." type errors. Too often I've heard the excuse "you can just ignore those errors, they're not important". They may not be important, but there's no reason the DBA or user running the script should have to see or be confused by them.
OK, so SQL Server doesn't have an equivalent of Oracle's one liner CREATE OR REPLACE but it's easy to check if an object exists before running the DROP / CREATE pair of statements. There are a few options available. If the object is a table or a view you can query INFORMATION_SCHEMA.TABLES to see if it already exists. For a wider coverage of objects you can query SYS.OBJECTS directly.
The approach can go something like this:
This simple step will make for much cleaner install logs where the only errors are ones that are worthy of attention.
This is just lazy and (when) lots of objects are involved it makes reviewing the installation logs difficult due to the large number of "Cannot drop the view...." type errors. Too often I've heard the excuse "you can just ignore those errors, they're not important". They may not be important, but there's no reason the DBA or user running the script should have to see or be confused by them.
OK, so SQL Server doesn't have an equivalent of Oracle's one liner CREATE OR REPLACE but it's easy to check if an object exists before running the DROP / CREATE pair of statements. There are a few options available. If the object is a table or a view you can query INFORMATION_SCHEMA.TABLES to see if it already exists. For a wider coverage of objects you can query SYS.OBJECTS directly.
The approach can go something like this:
IF EXISTS (SELECT 1 FROM INFORMATION_SCHEMA.TABLES
WHERE table_name = 'myView')
DROP VIEW myView
GO
CREATE VIEW myView AS .....
This simple step will make for much cleaner install logs where the only errors are ones that are worthy of attention.
Thursday, December 10, 2009
Monitoring a Long Running Stored Procedure
Recently I had the need to write a SQL Server stored procedure which performed numerous complex comparisons and wrote back numerous updates across many millions of rows. The result was a lengthy runtime. My client needed a means of quickly finding how far through the process was at any point in time.
I'm probably like many others and now just use the debugging ability of an IDE to get a look at what's going on inside a stored procedure, but that wouldn't work here. Way back when I'd PRINT statements to get information out to the messages pane but they won't display until a batch has finished and so couldn't be used here either.
The answer came in the form of RAISERROR WITH NOWAIT.
RAISERROR doesn't have to be used only with errors. In fact, for severity levels of 10 or less SQL Server will just treat them as messages, meaning that execution can continue on as normal, even when TRY / CATCH blocks are being used.
You'll need to ensure that the results are being sent to either text of grid (CTRL+T or CTRL+D in management studio) and click onto the messages tab of the output window in order to see the messages appear in real time.
Try this as an example:

When you execute the script you should see nothing for the first ten seconds with the first two messages then appearing before another ten second gap followed by the final message appearing.
Don't forget to click over to the messages tab in order to watch the action!
Monday, November 23, 2009
Oracle's MINUS and SQL Server's EXCEPT
Today I was a little surprised to find a difference between Oracle and SQL Server syntax that I wasn't aware of. I had a need to find a set of rows which had been incorrectly geographically coded. The incorrect coding took a number of forms and I wanted to make sure that I wasn't double counting.
Easy - I done the same type of thing many times before with Oracle. Just use the MINUS operator. Perhaps not. SQL Server complained about the MINUS keyword. With a little digging a found that the SQL Server equivalent is EXCEPT.
It does the same thing. It will return any rows from the first query where are not also returned by the second query. The syntax is:
SELECT col_a, col_b, col_c
FROM view1
MINUS
SELECT col_a, col_b, col_c
FROM view2
There are a few gotchas to be aware of. The number and order of the columns in the queries used must be the same, and the data types must also be the same.
I was even more surprised to find that the EXCEPT keyword actually is the ANSI SQL standard. Oracle's MINUS keyword is actually the odd one out!
Easy - I done the same type of thing many times before with Oracle. Just use the MINUS operator. Perhaps not. SQL Server complained about the MINUS keyword. With a little digging a found that the SQL Server equivalent is EXCEPT.
It does the same thing. It will return any rows from the first query where are not also returned by the second query. The syntax is:
SELECT col_a, col_b, col_c
FROM view1
MINUS
SELECT col_a, col_b, col_c
FROM view2
There are a few gotchas to be aware of. The number and order of the columns in the queries used must be the same, and the data types must also be the same.
I was even more surprised to find that the EXCEPT keyword actually is the ANSI SQL standard. Oracle's MINUS keyword is actually the odd one out!
Friday, November 13, 2009
Unexplained NULLs from Excel Sources in SSIS
Today when using SSIS to transpose some data I run into a problem which I'd seen before but had never had time to properly investigate and understand. Today the alternative to solving the problem was a lot of manual data manipulation so it was time to dig in and work out what was going on.
So, here's the problem, you may well have struck it yourself.
My Excel spreadsheet has a text column and three columns of integers.
And change it to this
So, here's the problem, you may well have struck it yourself.
My Excel spreadsheet has a text column and three columns of integers.
 But when I added an SSIS Excel Source and previewed the data I saw the following:
But when I added an SSIS Excel Source and previewed the data I saw the following:
 Rather than seeing the values of "Battery Point", 2, 1 and 1 for the first data row I had "Battery Point", 2, 1, NULL. Where had the value for the last column gone?
Rather than seeing the values of "Battery Point", 2, 1 and 1 for the first data row I had "Battery Point", 2, 1, NULL. Where had the value for the last column gone?
Some digging around MSDN led me to learn that the Excel driver reads 8 rows to determine the data type for each column in the source file. When a column has mixed data types the majority type wins, with numeric types winning over text types in the event of a tie. Cells in that column with the losing type(s) are given a NULL value. In my case I had one numeric cell and seven text cells in the first eight rows of the column. So my integer value of 1, despite the fact that it was in the first row, lost out under the collective weight of the following seven rows and was made into a NULL.
It is possible to avoid this by telling the driver to work in Import Mode. To do this bring up the Properties Page of the Connection object and add the value IMEX=1 to the extended properties of the connection string. You'll need to manually type the value into the connection string rather than using the ellipse or you won't be able to make the change.
So, in my example I start with this
And change it to this

A quick check of the preview from the Excel source reveals my value of 1 is back - the NULL is gone!
By the way, it's also possible to change the number of rows that Excel samples to guestimate the data type for each column to something other than the default value of 8. This is done by altering the registry key HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Jet\4.0\Engines\Excel and changing the value of TypeGuessRows to your new value.
Thursday, November 12, 2009
Reporting Services Parameters - Something to Avoid
Recently I had a need to review some SSRS reports and came across one of my pet report development hates - querying an inappropriate table to generate a list of values for a parameter pick list.
In this case the query that the parameter used was performing a table scan on a 35 million row transactional table in order to generate two values to display as potential parameter choices. I suspect that in development that performance was quite snappy and so no-one bothered to consider the efficiency of the SQL statement behind the parameter list. Even now (in a production environment) performance wasn't annoyingly bad - sub 2 seconds to return the values required. But consider the situation where the table is growing by tens of thousands of rows per day. The cost of the parameter query will become higher over time (as the size of the table grows) and the load on the database server will be higher than it need be, a problem that may well be compounded if the same design approach has been used across many reports on the server.
So what are the alternatives?
Ideally, take a look at the data model to see if there is already a table which models just the data for the parameter. For example, rather than querying a transactional hospital admissions table to get a list of hospital names, look for a table which contains information at the hospital grain - i.e. one row per hospital. Chances are if the entity is important enough to be required for a parameter it will already be modelled in the data model. This is particularly true in star schemas - look for a dimension table.
If that can't be done other things that might work include adding a table to the database, querying a smaller transactional table or adding an index to the transactional table which covers the column containing the values required for the parameter. Any of these approaches have potential implications on other interfaces to the database and so shouldn't be made without consultation and consideration.
In this case the query that the parameter used was performing a table scan on a 35 million row transactional table in order to generate two values to display as potential parameter choices. I suspect that in development that performance was quite snappy and so no-one bothered to consider the efficiency of the SQL statement behind the parameter list. Even now (in a production environment) performance wasn't annoyingly bad - sub 2 seconds to return the values required. But consider the situation where the table is growing by tens of thousands of rows per day. The cost of the parameter query will become higher over time (as the size of the table grows) and the load on the database server will be higher than it need be, a problem that may well be compounded if the same design approach has been used across many reports on the server.
So what are the alternatives?
Ideally, take a look at the data model to see if there is already a table which models just the data for the parameter. For example, rather than querying a transactional hospital admissions table to get a list of hospital names, look for a table which contains information at the hospital grain - i.e. one row per hospital. Chances are if the entity is important enough to be required for a parameter it will already be modelled in the data model. This is particularly true in star schemas - look for a dimension table.
If that can't be done other things that might work include adding a table to the database, querying a smaller transactional table or adding an index to the transactional table which covers the column containing the values required for the parameter. Any of these approaches have potential implications on other interfaces to the database and so shouldn't be made without consultation and consideration.
Monday, October 26, 2009
Crystal Reports Multi-line If - Then - Else blocks
I've been working with some inherited Crystal Reports today and came across something that I've seen a few times in the past as well. So, I suspect there might be quite a few folks out there who aren't aware of the way to write IF-THEN-ELSE blocks in Crystal Reports when more than one line is required to be executed in each of the code blocks.
The most likely way someone might try would be:
Most people seem to hit this error and get around it by just building a different IF-THEN-ELSE block for each of the lines, so if there were 10 lines in each of the blocks there would be 10 almost identical IF-THEN-ELSE statements.
 There is a better way. The trick is to convince Crystal that you only have a single statement in each of the code blocks - i.e. one statement for the IF block and another for the ELSE block. You can do this by enclosing each block in a set of parameters, like this:
There is a better way. The trick is to convince Crystal that you only have a single statement in each of the code blocks - i.e. one statement for the IF block and another for the ELSE block. You can do this by enclosing each block in a set of parameters, like this:

The most likely way someone might try would be:

But, alas, this won't work. You'll get the following error:

Most people seem to hit this error and get around it by just building a different IF-THEN-ELSE block for each of the lines, so if there were 10 lines in each of the blocks there would be 10 almost identical IF-THEN-ELSE statements.
 There is a better way. The trick is to convince Crystal that you only have a single statement in each of the code blocks - i.e. one statement for the IF block and another for the ELSE block. You can do this by enclosing each block in a set of parameters, like this:
There is a better way. The trick is to convince Crystal that you only have a single statement in each of the code blocks - i.e. one statement for the IF block and another for the ELSE block. You can do this by enclosing each block in a set of parameters, like this:
There key thing to remember when doing this with an ELSE clause is to make sure that the semi-colon for the last line of the code for the IF block is inside the closing bracket for that block. If you don't then Crystal will think that the semi-colon is terminating the entire IF-THEN-ELSE block.
Thursday, October 15, 2009
Controlling Colours in Reporting Services 2005
People familiar with Excel's chart wizard will know that it is very easy to set colours for a data series. It's very much a graphical point and click process. Things aren't quite so easy or obvious with Reporting Services. I've seen this cause problems during past development projects which consolidate reports from spreadmart sources into a central BI service centre. Often users will have developed Excel based reports with particular colours in various charts and will want those colours carried forward into the new centralised Reporting Services versions of those reports in order to convey or highlight meaning. I have seen developers tell end users that the colour selections can't be carried across as the new tool lacks the functionality to control colour.
This isn't true. It may not be immediately apparent - but it is reasonably straightforward to set the colour for a data series. If only one colour is required then it can be set by following the steps below:

This isn't true. It may not be immediately apparent - but it is reasonably straightforward to set the colour for a data series. If only one colour is required then it can be set by following the steps below:
- Open the Chart Properties
- Select the Data tab
- Press the Edit button for the Values section
- Select the Appearance tab
- Press the Series Style button
- Select the Fill tab
- Press the Colour button
- Select the colour required.

It's also possible to control the colour of different elements within the chart. The example below shows discharges from a health care facility across various blocks of time during the day. The chart can be given more impact by highighting discharges that occur outside of the expected times. To show this we set the colour of bars for the worst times to be red, the bars for the less severe breaches to be yellow and the remaining bars for discharges in compliant times to be green.
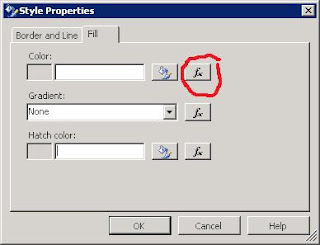
A little code is required to achieve this. Firstly bring up the Style properties window in the same way as you would to just set one colour. But rather than using the colour button, select the function button that sits beside it.

The following code will set the colour of the chart's bars.
=Switch(Fields!TimeBlock.Value = "1600 - 1800" OR Fields!TimeBlock.Value = "Unknown", "Yellow", Fields!TimeBlock.Value = "Pre 10am" OR Fields!TimeBlock.Value = "1800 - 2400", "Red", 1=1, "Green")
The Switch statement in Reporting Services works in much the same way as T-SQL's CASE statement. There is no specific equivalent of the ELSE part of the CASE statement. In this example I've used an expression which will always be true (1=1) to force a default colour of green.
The end result is a chart in which the colours are not automatically set by SSRS, but rather are choosen and selected based upon data values found at runtime.

Monday, October 12, 2009
Formatting Total Rows and Columns with Reporting Services
I’ve not had a need to build a matrix report in Reporting Services. Most of my past projects that needed these types of reports all seemed to have Crystal Reports as the report development tool. Crystal’s crosstab reports handle this requirement easily and are quite intuitive to use (or perhaps it just seems that way to me as I’ve used the tool for such a long time now).
I expected Reporting Services’ matrix to be similarly easy to use, and in general it was. I had the skeleton of my first matrix report up and running in only a few minutes. But when it came time to tidy up the formatting I struck a stumbling block. I wanted my report to have both column and row totals with a bolded typeface. Easy? Click on the total textbox and set the font weight - right? The report preview suggests that's not the case. While the column and row headers are bold - the totals themselves are not.
All being well you shoud now have bolded row and column totals!
I expected Reporting Services’ matrix to be similarly easy to use, and in general it was. I had the skeleton of my first matrix report up and running in only a few minutes. But when it came time to tidy up the formatting I struck a stumbling block. I wanted my report to have both column and row totals with a bolded typeface. Easy? Click on the total textbox and set the font weight - right? The report preview suggests that's not the case. While the column and row headers are bold - the totals themselves are not.
 After a bit of trial and error I found where I was going wrong. The trick is to ensure that you edit the properties of the textbox (which affects the row or column label) but you also edit the properties of the subtotal as well. You get to this by ensuring you click on the green symbol in the top right corner of the textbox.
After a bit of trial and error I found where I was going wrong. The trick is to ensure that you edit the properties of the textbox (which affects the row or column label) but you also edit the properties of the subtotal as well. You get to this by ensuring you click on the green symbol in the top right corner of the textbox.

Click on the green area and look at your properties window - it should now be showing the subtotal properties. Format away. If, like me, you simply need a bold typeface then expand the Font property group and set the FontWeight property to Bold.
All being well you shoud now have bolded row and column totals!

Friday, October 9, 2009
Dynamic Chart Titles with SQL Server 2005 Reporting Services
In browsing some forum postings recently I ended up here: http://social.msdn.microsoft.com/Forums/en-US/sqlreportingservices/thread/bcb6b640-a4bd-4040-8954-679b89f61caa.
I noticed the comment that there was no support for using parameters in chart titles in SSRS 2005, only in SSRS 2008. I’ve always been lucky enough to have access to the full Dundas Charts product when working with SSRS 2005 on past projects, but am now working on a project where we only have access to the standard SSRS2005 chart control so was curious if this (suggested) limitation would prove a problem or not.
So I created a quick test report and added a chart control. Bringing up the properties window showed that the chart title had an option to deal with basic formatting, but indeed no expression builder.
 Undeterred, I added a report parameter and I tried simply typing in a chart title which contained parameters:
Undeterred, I added a report parameter and I tried simply typing in a chart title which contained parameters: =Parameters!ParameterName.Value + " the rest of my chart title"

A switch to preview mode showed it worked. The chart title changed dynamically at run time with the parameter value.
Given that win I decided to push my luck and see if I could add some more complex logic. So I added a second report parameter and typed the following expression in the chart title textbox:
=IIf(Len(Parameters!ParameterName.Value) >1, Parameters!ParameterName.Value + " the rest of my chart title", Parameters!SecondParamterName.Value + " the rest of my chart title")
Back in to preview mode and again success!
So it would seem that there is support for the use of parameters in SSRS2005 chart titles after all.
For more complex expressions I tried creating a textbox on the main report palette as a scratchpad so I could use the expression builder and save the need to type the entire expression. From here it was a simple matter of a copy and paste across to the chart title textbox. The only shortcoming I found was that the title textbox is only single line so I needed to ensure that my expression had no line breaks in it. Failure to do this would result in only the first line of the expression being pasted successfully.
Those people lucky enough to be working with SSRS 2008 have an expression builder inside the chart title properties, but for the rest of us this approach provides a reasonably painless alternative.
Subscribe to:
Comments (Atom)


